
让不懂建站的用户快速建站,让会建站的提高建站效率!


据多家泰斗询查机构最新研判,2026 年 中枢存储供应链的结构性缺少已成行业刚性推行,供需缺口合手续扩大且很可能不时至 2027 年。不仅是存储部件的单点问题,现时,生成式 AI 正从时刻尝鲜全面走向规模化落地,大模子时刻的垄断场景正在从教练为主转向训推并重和轻量推理,PD 分离、KV Cache 等时刻的规模化垄断在合手续擢升推理恶果的同期,对高带宽、大容量的 GPU 内存建议了极致严苛的条目,显存资源垂死带来的行业惊险正在合手续蔓延。叠加存储部件供应缺少与价钱跳升的双重压力,AI 产业发展靠近严峻的资源与资本挑战,单纯依靠 “力大砖飞” 的硬件堆叠,不仅会大幅推高每 token 资本,更受供应链产能制约难认为继,严重影响产业良性发展。
因此,通过软硬件协同优化擢升 GPU 等关键部件的使用恶果,成为破解内存供应链缺少惊险、虚构总体领有资本的中枢旅途。
破局窘境·架构解密:新华三打造智算推理新引擎
现时,大模子推理靠近的发展窘境已弗成秘密:模子对算力与显存的需求呈指数级增长,相干词堆叠GPU硬件所带来的资本与能效压力,严重制约时刻的可合手续发展。尤其在处理长文本、多轮对话等场景时,模子为保存陡立文而生成的KV Cache(键值缓存)会急剧彭胀,不仅多数占用可贵的GPU显存,更导致多数重迭设想,成为制约反应速率、推高运营资本的瓶颈。
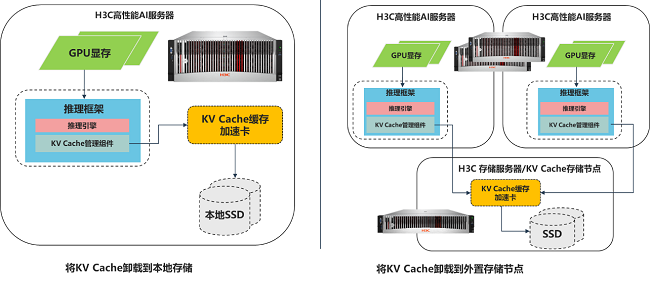
直面资本与恶果的核肉痛点,紫光股份旗下新华三集团打造出效率兼备的大模子推理场景加快决议。通过其自研的定制化ASIC芯片提供硬件级加快,将KV Cache从GPU内存卸载到指定存储节点,构建专为AI设想的“下一代内存层”,削弱GPU显存的压力,从而在系统层面罢了了存算资源的新均衡。新华三凭借自己纷乱的硬件集成与全栈优化能力,驱动业内前沿科技与自研AI奇迹器的编削耦合,经过深度的测试调优最终酿成了大模子推理加快的最好执行,为业界提供了一条性能与资本兼顾的全新推理范式。
从部署形态来看,本决议既撑合手单机形态部署,径直提高单台AI奇迹器的推感性能。也撑合手通过外置存储节点的样式同期对接多台AI奇迹器,提高集群的推感性能。
实历练证·性能跃升:中枢贪图翻倍,推升深度推理新速率
为真切琢磨本决议中KV Cache卸载对推感性能的擢升,新华三基于自研高性能AI奇迹器进行基准测试,要点关怀在兼并机型上,开动DeepSeek-V3-671B模子时,继承模范推理奇迹和继承KV Cache卸载加快决议的两种模式下的性能各异,分辨构建10K和30K的文本输入,模拟本色垄断场景中的多轮对话推理经由,以确保测试休止具有本色参考价值。经多轮考证,继承KV Cache卸载加快决议的推理中枢贪图显耀优化:
• 并发用户数擢升200%:在疏通TPOT(每个Token生成的平均延长,ms)收尾下,通常的算力资源可撑合手的并发数显耀擢升,保险用户体验的同期撑合手奇迹更多的用户。
• 推理延长大幅虚构:TTFT(首Token生成的延长,ms)虚构70%,TPOT(每个Token生成的平均延长,ms)虚构30%,大幅裁减反应延长,擢升用户体验。

场景适配·全域遮掩:贴合企业GenAI落地需求
• 交互式垄断(多轮对话): 如聊天机器东谈主、智能客服等。这类垄断中,用户与模子的交互是多轮的,后续轮次的输入时常依赖于前序对话的陡立文。通过快速加载存储历史 KV Cache,省略大幅裁减反应延长,擢升用户体验。
• 长陡立文处理: 关于需要处理数千以至数万Tokens陡立文的任务(如长文档问答、代码生成、复杂提醒认知),GPU内存容量时常成为瓶颈。本决议提供的PB级KV Cache扩展能力,使得处理这类长陡立文任务更为安靖,幸免了因GPU内存不及导致的性能着落或任务失败。
• 高并发推理奇迹: 在面向多数用户的在线推理奇迹中,系统需要同期处理多个并发恳求。本决议通过高效的KV Cache处罚,省略撑合手更多并发会话,显耀提高系统的全体朦拢量(RPS),从而在疏通的GPU资源下奇迹更多用户。
跟着模子规模的扩大和用户基数的扩张,大模子推理恶果正成为AI基础模范性能的关键贪图。新华三凭借多年来在AI规模的时刻编削与执行探索推出推理加快决议,并进行经心的调优执行,充分考证了该决议在擢升推理恶果方面的显耀上风,进一步加快GenAI垄断的发展。
GenAI期间,推理加快注定是一条合手续擢升、永无尽头的编削之路。面向改日,新华三将合手续在AI Infra规模深耕,提供更多针对不同场景,设想基于不同加快层级、不同加快介质等时刻道路的推理加快决议,匡助企业和成就者更冒昧地叮咛大模子落地垄断的复杂性和规模挑战,鞭策AI时刻在更多规模的垄断和编削。
股票配资平台开户_实盘交易流程指南提示:本文来自互联网,不代表本网站观点。







